> There will not be a [..] process for submitting patches by [any] means
> Outside involvement still matters: clear bug reports
So I can find a bug, I can fix it, but I am not allowed to tell them how exactly I did it.
Instead they have to re-figure it out. The team must be thrilled to re-do work they know was already put in by others, repeatedly.
As a user-and-eveloper, why would I sink time into a project with such rules that put a barrier to improving my life with the software? It seems much easier to use Firefox or Chromium, where my fixes actually meet open ears.
It was very useful for me in the past when a new Chromium version crashed on my product, that I could go and suggest a fix to V8, and it was rolled out in the next Chromium release so my product worked again (https://github.com/v8/v8/commit/4f8a70adca01c). Without this, maybe Chromium developers would have never bothered to fix it because of lack of time to figure it out.
> a pull request no longer tells us as much as it used to about the person submitting it
Nobody should need to know anything about any person submitting a pull request.
Hopefully whether code that makes it into Firefox or Chromium was never based on the "effort" or "faith" of the submitter, but based on the correctness of the code in review.
Reviewing code fixes is strictly easier than coming up with them yourself.
This holds true automatically: In any situation where it isn't, you can just write the code yourself and done.
As a project you can always ignore or close a PR you want to write yourself instead.
But it seems unwise to bar yourself from the _option_ of reviewing an outside contribution, or using it as input for your own re-write.
> So I can find a bug, I can fix it, but I am not allowed to tell them how exactly I did it.
Pin pointing the issue is way more than valuable than code. If you wrote a fix, you have analyzed the bug. The value is there, not in the fix. Sharing your fine analysis is the maximized contribution. Code is an optional bonus at most.
'I applied this change to my local fork as a temporary workaround, in case it's useful to consider' is the way to express this.
In one memorable case, by presenting it as problem+tempfix and inviting discussion, the developer argued that I should focus on repairing the other software that was the cause of brokenness. I agreed with them, we mutually closed the issue, and my code was (correctly) discarded.
Code is a secondary and optional part of the feedback process. Yes, it can be a more precise language for conveying a problem report. No, it is not necessarily a boon. Code never carried significant intrinsic value — the motivation of the author to show up and interactively participate with the project that was infinitely more valuable than any one patch! — and now with AI, code carries negative intrinsic value, indicative of drive-by patches with no likelihood of future participation.
The most effective contribution I made this month to a project was to spend three weeks reproducing a bug and then informing them of the process to repro it themselves. They were head over heels grateful, not only because I bothered to write a bug report, but because I followed up a week later when I managed to create a second repro case of the exact same issue under wholly different circumstances. The issue is, at its core, a reasoning error about a protocol handshake-setup-command process across 2+ devices, and patching their code to fix it is meaningless compared to the value I provided by simply showing my work in tracking down the problem.
Pull requests are, these days, more often an expression of entitlement ('I deserve praise, be grateful for my code, comply with my designs, or else') than of free-time invested into the project ('Hi, we've been working together in various bug reports for a while, and I saw this problem and felt like it would be a fun side project to hack on') and so I wholly endorse their decision to refuse them.
exactly. a _proposed_ code fix is a good indicator where the problem is (analysis) but more often than not the actual maintainable and sustainable solution will look different.
a code owner may choose a very different way of fixing things, even for what looks like a trivial fix.
Reviewing code in PRs is not a no-effort action. If there are 3 people working in the project, and thousands of people submitting bugfixes, then no matter how useful those bugfixes might be, the 3 people will be totally overwhelmed by the sheer number of PRs.
There might be value in your bugfix, but maybe that value is not greater than the cost of reviewing and accepting it.
> Reviewing code fixes is strictly easier than coming up with them yourself.
This is completely false, for any sufficiently complex project. The fix might be a single line change, but the consequences might be far reaching.
> As a user-and-eveloper, why would I sink time into a project with such rules that put a barrier to improving my life with the software?
Please don't! You don't owe the project anything. The other side of that equation is that the project also doesn't owe you anything. As simple as.
Firefox and Chromium are running much larger teams, let alone the Linux kernel, that other people suggested as a model. Maybe they can afford accepting your contributions.
> Nobody should need to know anything about any person submitting a pull request. Hopefully whether code that makes it into Firefox or Chromium was never based on the "effort" or "faith" of the submitter, but based on the correctness of the code in review. Reviewing code fixes is strictly easier than coming up with them yourself.
You state these things as if they are facts, but they are completely contrary to the lived experience of open source maintainers - not only my own and the TFA's but quite a large number of others who have shared similar pieces.
Would you mind sharing a link to one of the open source project you've been maintaining and reviewing contributions on for years that forms the basis of your expertise on this matter?
Yeah, I am employed by an open source company (to be clear not open core) and most of the external code contributions we get are a net cost for us. It takes more time to review than it would have taken for our team to code and review.
The real value we get from being open source is high quality bug reports and trust from our customers, not the external contributions. The only reason we welcome external contributors is marketing and generally being welcoming. If LLMs make this cost even higher for us then we might have to stop accepting external PRs.
> Would you mind sharing a link to one of the open source project you've been maintaining and reviewing contributions on for years
Github is in my profile; I am nixpkgs committer for ~10 years (which is one of the most active projects on Github with 450000 merged PRs).
There is no way I could have possibly written and (pre-tested, to arrive at the eventual code submitted) all the code that I have reviewed.
From the other side, I have spent thousands of hours debugging and writing PRs to over 100 FOSS projects (e.g. glibc, busybox, util-linux, lz4, GHC and tens of Haskell packages, Jenkins, Chromium, GTK, Consul, OpenCV, Signal, many more).
Many of them are small or medium fixes ("drive-by fixes"), where you propose a PR, the owner reviews, says "great, thanks", and the bug gets fixed.
This is a fundamental workflow for open source work. The project gets free contributions and time investment outsourced to "the community" who fix its bugs, the developer-users/community get their problems fixed upstream, permanently.
This not possible for projects that don't have an easy way to submit code with low effort for both sides.
Accepting drive-by fixes is what clears up developer time and helps clear out the countless small issues in software.
If AI slop PRs are a problem, it seems better to establish clear rules and reject contributions that don't follow them with a single click, rather than banning developer contributions altogether. It seems to work acceptably for nixpkgs so far.
Thanks for your work on nixpkgs but I think that shapes your perspective quite a lot - its a very different project from Ladybird. Not to belittle your contributions there but the majority of commits there are a few lines of code and much of it is declarative. I'm sure a lot goes into review of entirely new packages and there are some complex interactions between dependencies to consider on some changes but not in a program structure or logic sense. Vibe slop may not be so much an issue there.
It is simply a fact that most commits are small - that is the nature of that kind of project. I looked at the commit history. It still takes a lot of work and it is valuable, but it has very different review requirements.
Ok, how come your little comprehension examination didn’t grapple with the main point: that they said they could not have made the changes they merged in themselves? Surely pointing out that the commits were small cuts AGAINST your whole argument. For a more complex project where vibe slop might not be appropriate (again, wild thing to say), the potential input from outside is more valuable, not less.
You can still tell them how you did it, just not in the form of code/patches. You should be able to describe it in prose so that the maintainer understands your solution approach.
Not necessarily. I just fixed the Ladybird build process so it will successfully build on a system that uses musl instead of glibc. By far the most compact way of explaining what needed to be changed is to share the changes themselves. It is a set of very small changes to a number of individual files.
That sounds more like a new feature than a bugfix, however. That aside, I didn’t claim that it would necessarily be more compact, just that it’s possible. Any change can be described in prose, to whatever level is necessary to get the essential insights across. It’s how the ancient greeks did mathematics, they didn’t have symbols or formulas.
Exactly. You want others to change to fulfill your needs. Their priorities and needs are different. In this case, it was evaluated and found not to be useful (cost > benefits).
> I can find a bug, I can fix it, but I am not allowed to tell them how exactly I did it.
You can do all that, and make a bug report with a fix.
What happens next is up to the maintainers. If they reimplement from everything you gave them, and sculpted the fix into its final shape, that’s a great outcome for everyone.
> You can still submit a bug report and tell them exactly how you did it.
Can you? The announcement says "There will not be a separate process for submitting patches by other means. We do not want to create a shadow contribution system through issues, comments, email, or forks".
So I, as a human, describe in prose which changes I made to e.g. 20 files?
How is that in the spirit of fighting LLM slop?
Also, if I can do that, the LLM slop contributers can also ... do that.
In contrast to Microsoft, OpenAI, and Anthropic, AWS has never done anything close to sneaking in unwanted training opt-outs after the fact.
They are the only ones I trust not to do that so far. And their terms are extremely clear on that, no fuzzy language. Exactly what we want to see. So we use Bedrock.
No, this is not the reality of using Haskell packages.
The problem you describe was solved more than a decade ago.
You use a Stackage snapshot (https://www.stackage.org/lts) which is a curation of packages that work together, similar to a Linux distribution like Debian, carrying one version per package.
Our company using Haskell has not spent 1 minute doing "dependency resolution" in the last 10 years, not has anybody we know.
The what is the idea behind the "ideally have already read the paper, but given 10-20 minutes in silence" part?
The fact that people that have already read it have nothing to do and waste time sitting around bored sounds like an obvious flaw, are we missing something?
I take issue with the “ideally have already read the paper” part. That’s actually not true for most of the attendees. There will be some who have, though, and those will be your co-authors or others who have helped you prepare it before the meeting. And they don’t mind waiting in silence during the reading period, because they have a stake in the outcome.
Also, 20 minutes of respite isn’t necessarily “waste.” Having 20 minutes of time to think deeply on something is often a gift!
Can you really think deeply in 20 min, while on zoom or in a meeting room?
I think this gets to the heart of my complaint. I thought this would increase the water level on our technical discussions. It hasn't. Like I say, could be the documents or people are poor. In any event, I'm one person that believed in this right up until my org implemented it.
We’re talking about the quiet reading period here. If someone has already read the document or participated in its authorship, they get 20-30 minutes of silence to think about whatever they’d like. And yes, those minutes can be a useful respite from an otherwise hectic day.
I have no idea how your org implemented the table read, so I can’t comment on why it may not have been effective there.
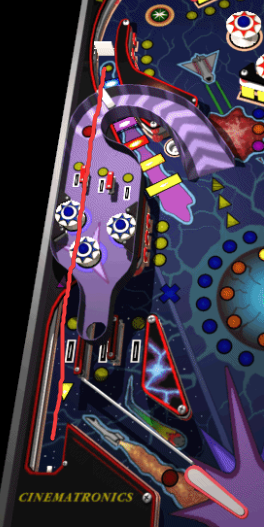
Many people have thought about this, IIRC it's not physically possible to build because there is a lane that goes under a bumper (which in real life they extend down quite a bit) https://files.catbox.moe/pnaeri.png
Assuming that it's about moving the ball unseen (which makes it much easier) from the sink hole higher on the table to the apparent ejection hole and kicker low on the table.
One could have the ball go quite low below the table surface and then use some kind of mechanical kicker to get it up to table level again near the bottom. It's possibly a unique problem, but seems to be much less work than building the rest of the table.
Or just have a different ball ready to come out of the exit hole, the top hole would swallow ball 1, and a different ball could exit after a realistic delay...
A bit like Star Trek teleportation.. is it you, or a copy of you?
Several real pinball tables do this, keep a hidden ball staged to make it seem to instantly reappear. The Rick & Morty machine in particular does this - you can shoot into a portal, and the ball (actually a different hidden one) reappears instantly some distance away.
Pop bumpers on an elevated/overlay playfield seems like a nightmare in general, maintenance would be a big pain. I can't think of a machine that has a pop like that, but my internal pinball database is getting pretty dusty.
You might be able to make the kickback lane work with a subway or maybe make the machine a widebody and go around the mess?
I think it's because the bumpers on top (the white things with the blue dot in the middle) need a lot of space underneath and the line runs through the space that they would need.
The purple thing is an overlay... There's the ramp, the three lanes (with lights), three blue mini pop bumpers, and then the ball drops into the inlane for the left flipper.
The kickback puts the ball into the left orbit, which is at ground level, the ball will hit the spinner and then IIRC cause it's outside the crop, it goes into the lanes at the top of the playfield, and into the pop bumper area there.
I suggested this to a Stern employee 21 years ago, which obviously went nowhere. Back then they were trying to do a Halo machine, which also went nowhere.
Even then, I also share the confusion of the poster you're replying to.
I don't see how a virtualised NVMe disk is different from a physical one.
Especially if you don't have control over the underlying hardware (so you don't know if it has power-loss-protection PLP SSDs), you should send the FUA.
> O_DATA_SYNC
You mean `O_DSYNC`?
Why would you need `O_DSYNC` on-premise, but not on cloud VMs? (Or are you saying you'd include it everywhere?) Similar to my above point, surely it is the task of the VM to pass through any FUA commands the VM guest issues to the actual storage?
Further: Is `O_DSYNC` actually substantially different from writing and then `fdatasync()`ing yourself?
My understand is that no, it's the same. In particular, the same amount of data gets written. So if you believe that to avoid the "can trigger an order of magnitude more I/O" by avoiding `fdatasync()`, you would re-introduce it with `O_DSYNC`.
However, I suspect that that whole consideration is pointless:
The only thing that makes your O_DIRECT+preallocated-only-overwrites writes safe are enterprise SSDs with Power Loss Protection (PLP), usually capacitors.
On those SSDs, NVMe Flush/FUA are no-ops [1]. So you might as well `fdatasync()`/`O_DSYNC`, always. This is simpler, and also better because you do not need to assume/hope that your underlying SSDs have PLP: Doing the safe thing is fast on PLP [2], and safe on non-PLP.
So the only remaining benefit of `O_DSYNC` over `fdatasync()` is that you save a syscall. That's an OK optimisation given they are equivalent, but it would surprise me if it had any noticeable impact at the latencies you are reporting ("413 us"), because [2] reports the difference beting 6 us.
Let me know if I got anything wrong.
The only remaining question is: Why do you then see any difference in your benchmark?
Thanks for the feedback, since I have relied in other thread related to O_DSYNC which a lot of folks have already suggested, and I will not repeat it here.
For the benchmark results, and they were mainly due to metadata management. We have implemented our own KV store, see internal here [1], which is more efficient than ext4 namespace management, even after doing very aggressive fs tuning for that [2] (plus 65536 sharding for each leveled dir).
Fsync on PLP drives isn't strictly a NOP - you still take a latency hit from the round trip of the command to the NVMe device, where it is implemented as a NOP.
Thanks for pointing it out the mistakes. We should make it clearer, when fsync an opened file descriptor, it would only sync its own metadata. To make it truly persistent, we need to issue another fsync for the directory fd, which would make it more expensive.
I’m curious: what happens when a file and its metadata are fsync’d, but the dirent is not and the system loses power? If the file is brand new, does it show up as an orphan upon reboot, or is it just gone? Can you somehow access it by inode even if it’s not findable? Is this filesystem specific?
Is there something else weird that can happen if the file is not new, not unlinked, but changes are made that would alter the directory entry in it in some way?
Given the commit is 4 weeks old, will it eventually get comments?
The code before the patch does not look obviously wrong. Now, some more lines were added, but would you now say it now looks less obviously wrong, or more obviously correct?
It seems that the invariants needed here are either in some person's heads, or in some document that is not referenced.
Reading the code for the first time, the immediate question is: "What other lines might be missing? How can I figure?"
If the "obviously correct" level of the code does not increase for a human reviewer, how is it ensured that a similar problem will not arise in the future? Or do we need more LLM to tell us which other lines need to be added?
Yeah, the test with the patch also adds comments. The human reviewer had extra context available.
I did get Opus to do an audit for similar problems elsewhere, to supplement the investigations that we were already doing by hand. It initially thought it found something, but when asked to produce a testcase, it thought for 20 minutes and admitted defeat. I suspect that the difference between Opus and Mythos is in small edges like this: if Mythos is smart enough to spot why Opus's discovery didn't work a little bit faster, and it can waste less time chasing down red herrings, then it's more likely to find a real bug within the limits of a context window. It's not that Opus completely lacks some capability, it's that it has trouble chaining all the pieces together consistently.
A big benefit of piezo-powered electronics is that they can do all the usual stuff, such storing state, or cryptography to prevent spoofing, which the ultrasonic approach from the article cannot do.
{kind=link}
reply